| Task | ReVLA | OpenVLA |
|---|---|---|
| Pick up the lobster and place it on the plate (OOD Objects) | 4/10 | 0/10 |
| Place the cup on the blue plate (Visual Recognition) | 5/10 | 2/10 |
| Pick up banana and place it in the pan (Indomain Task) | 8/10 | 9/10 |
We tried OpenVLA-Bridge but it performs worse than OpenVLA, so we compare only with OpenVLA.
We demonstrate the capabilities of our method on a real robot, in this case the WidowX robot. The robot is prompted with language instruction and a single 3rd person view uncaliberated image.
ReVLA
OpenVLA
Task Prompt: Pick up the lobster and place it on the plate
ReVLA
OpenVLA
Task Prompt: Pick up the cup and place it on the specified plate
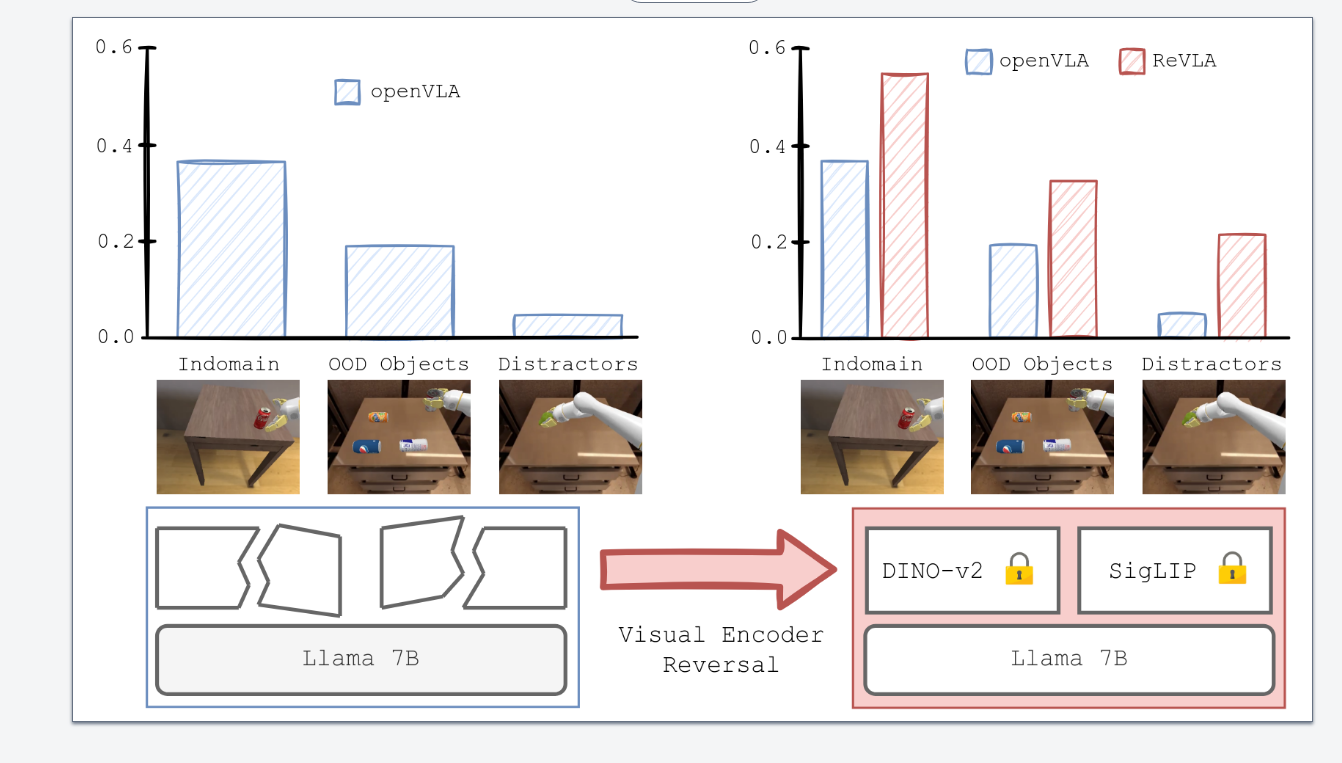
Indomain Task + Objects: We use the same objects as in the bridge dataset and test performance on indomain tasks.
ReVLA
OpenVLA
Task Prompt: Pick up the banana and place it in the pan
@misc{dey2024revlarevertingvisualdomain,
title={ReVLA: Reverting Visual Domain Limitation of Robotic Foundation Models},
author={Sombit Dey and Jan-Nico Zaech and Nikolay Nikolov and Luc Van Gool and Danda Pani Paudel},
year={2024},
eprint={2409.15250},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2409.15250},
}